Abstract
Aerial robots interacting with objects must perform precise, contact-rich maneuvers under uncertainty. In this paper, we study the problem of aerial ball juggling using a quadrotor equipped with a racket, a task that demands accurate timing, stable control, and continuous adaptation. We propose JuggleRL, the first reinforcement learning-based system for aerial juggling. It learns closed-loop policies in large-scale simulation using systematic calibration of quadrotor and ball dynamics to reduce the sim-to-real gap. The training incorporates reward shaping to encourage racket-centered hits and sustained juggling, as well as domain randomization over ball position and coefficient of restitution to enhance robustness and transferability. The learned policy outputs mid-level commands executed by a low-level controller and is deployed zero-shot on real hardware, where an enhanced perception module with a lightweight communication protocol reduces delays in high-frequency state estimation and ensures real-time control. Experiments show that JuggleRL achieves an average of 311 hits over 10 consecutive trials in the real world, with a maximum of 462 hits observed, far exceeding a model-based baseline that reaches at most 14 hits with an average of 3.1. Moreover, the policy generalizes to unseen conditions, successfully juggling a lighter 5 g ball with an average of 145.9 hits. This work demonstrates that reinforcement learning can empower aerial robots with robust and stable control in dynamic interaction tasks.
Aerial Ball Juggling Task
The task requires a quadrotor equipped with a flat racket to continuously strike a ball upward, sustaining an indefinite juggling sequence. At each contact, the quadrotor must precisely position the racket, control the impact force to redirect the ball to a target apex height, and then reposition for the next hit. This demands tight integration of agile flight control and precise dynamic manipulation under real-world uncertainties.
Compared to traditional manipulation tasks, aerial juggling presents unique challenges: the quadrotor is underactuated, the ball follows high-speed ballistic trajectories, and each hit must be accurately timed within a narrow contact window. We target an apex height of approximately 1.7 meters per hit using a standard ball and a lightweight racket.
Method
JuggleRL is built around a simulation-to-real pipeline that carefully addresses each source of the sim-to-real gap. The policy is trained with PPO over 2 billion frames in NVIDIA Isaac Sim across 4096 parallel environments, completing training in under 3 hours on a single GPU. It is then deployed zero-shot on a real quadrotor.
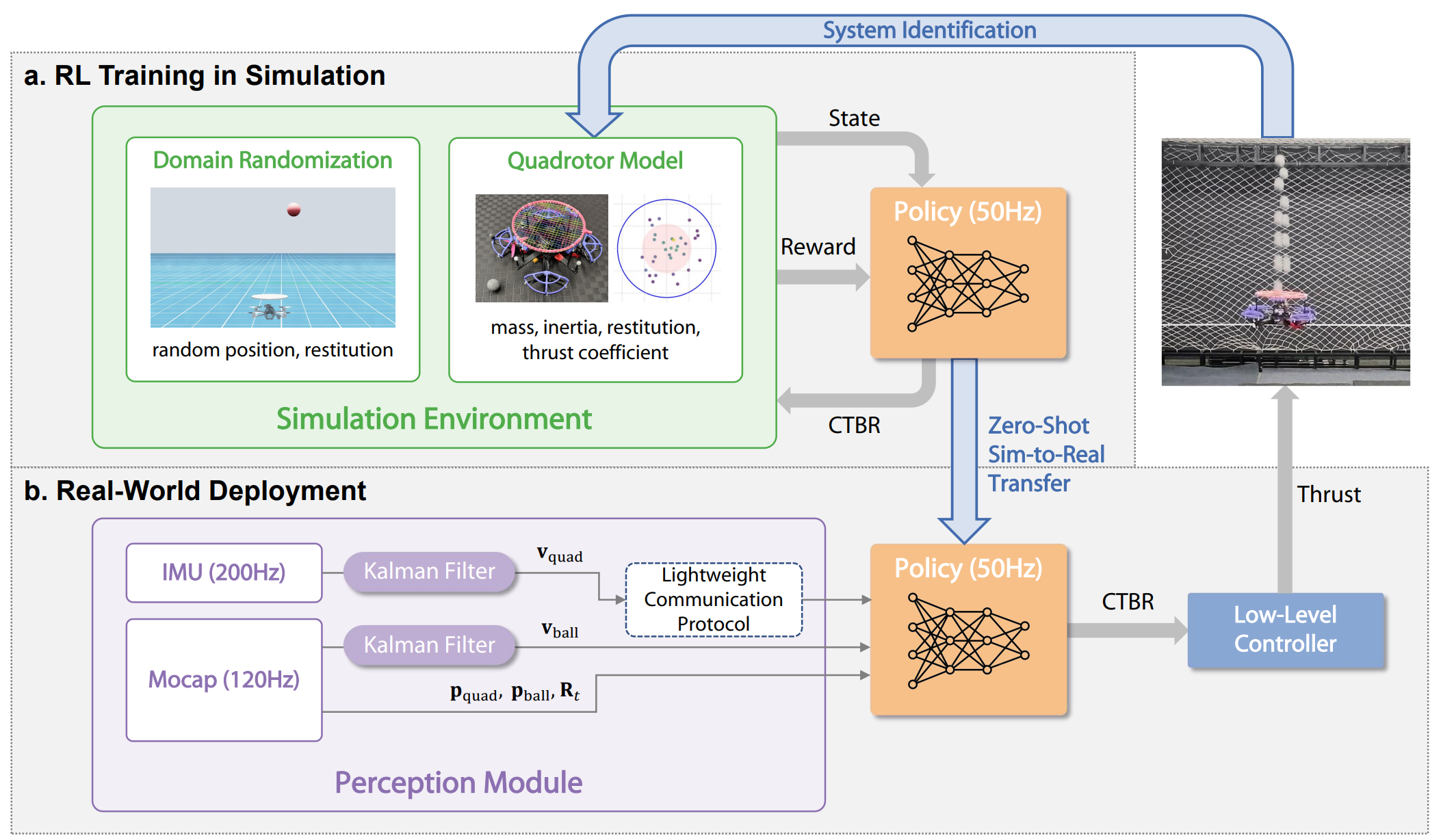
Figure 1. Method overview of JuggleRL. The system combines calibrated simulation, domain randomization, PPO-based large-scale training, and a Lightweight Communication Protocol (LCP) for zero-shot real-world deployment.
Simulation Calibration
Systematically measure physical parameters — quadrotor mass (1.090 kg), motor thrust coefficient (5.39×10⁻⁶), ball mass (0.047 kg), coefficient of restitution (0.82 center / 0.64 periphery) — to build a high-fidelity simulation.
Domain Randomization
Randomize coefficient of restitution [0.75, 0.90], ball release height [1.5, 2.0 m], and horizontal positions (±0.07 m) during training to produce policies robust to real-world parameter variations.
Reward Shaping
Combine sparse task rewards (hitting and apex achievement) with dense shaping rewards for racket-centered contact, sustained juggling, horizontal centering, motion smoothness, and yaw stabilization.
Lightweight Communication Protocol (LCP)
Custom low-latency protocol transmitting only essential motion states (pose and twist) at 200 Hz, enabling real-time closed-loop control and reducing deployment latency compared to standard ROS communication.
Policy Architecture
The policy takes a 24-dimensional observation vector including the quadrotor's absolute state (position, rotation matrix, linear and angular velocity) and ball state (absolute position, velocity, and relative position to the racket). The 4-dimensional action space outputs collective thrust and body rates (CTBR), which are executed by an onboard low-level PID controller.
Results
Real-World Performance
JuggleRL dramatically outperforms the model-based planning baseline (MBPP). Over 10 trials at fixed drop height (1.65 m), our policy achieves an average of 311 consecutive hits with a maximum of 462 hits, while the MBPP baseline reaches only an average of 3.1 hits and a maximum of 14.
| Method | Avg Hits | Max Hits |
|---|---|---|
| JuggleRL (ours) | 311 | 414 |
| JuggleRL — varying height (1.5–1.95 m) | 403.6 | 462 |
| MBPP (model-based baseline) | 3.1 | 14 |
Table 1. Real-world juggling performance. JuggleRL achieves over 100× the average hits of the model-based baseline.
Generalization to Out-of-Distribution Balls
When deployed on a lighter 5-gram ball (outside the training distribution), the policy achieves an average of 145.9 hits over 10 trials, demonstrating strong generalization despite significantly different ball dynamics and higher control sensitivity.
Ablation Study
We ablate each key design choice to validate its contribution. The results confirm that every component is critical:
- Without horizontal position randomization: 0.5 avg hits
- Without restitution randomization: 6.8 avg hits
- Without height randomization: 20.3 avg hits
- Without LCP (standard communication): 200.2 avg hits
- Full JuggleRL: 311 avg hits
Videos
Highlight Video
BibTeX
If you find our work useful, please cite our paper:
@article{ji2025jugglerl,
title={JuggleRL: Mastering Ball Juggling with a Quadrotor via Deep Reinforcement Learning},
author={Ji, Shilong and Chen, Yinuo and Wang, Chuqi and Chen, Jiayu
and Zhang, Ruize and Gao, Feng and Tang, Wenhao and Yu, Shu'ang
and Xiang, Sirui and Chen, Xinlei and Yu, Chao and Wang, Yu},
journal={arXiv preprint arXiv:2509.24892},
year={2025}
}